A new method named MonoXiver uses AI to build up reliable 3D maps of a camera’s surroundings based only on 2D photos. The technology could be especially useful for navigation in self-driving cars.
As 2D representations of a 3D world, photos are missing a huge amount of information about the actual sizes of the objects they portray, as well as their distance from the camera (and each other). These issues with depth and perspective sometimes make for weird, fun optical illusions, but it becomes a serious problem if you need to navigate the real world using 2D cameras. The problem is especially restricting for self-driving cars, which must constantly scan the road to keep track of potential objects, and the paths and positions of other cars. Without a reliable 3D map of their surroundings, the software driving the vehicles are prone to making mistakes. So far, this has been one of the main barriers to the widespread adoption of self-driving technology. There are already a few ways around the problem. Today, one of the most widely used techniques involves combining photos with LIDAR, which builds up 3D maps by sending out laser beams in multiple directions, and measuring how long it takes for the light to bounce off surrounding objects. Yet this technology is costly, and the hardware can be difficult to integrate with modern car designs.
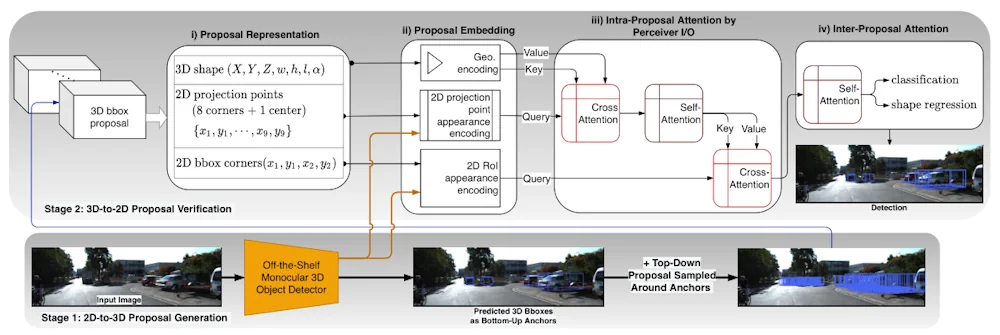
A team of researchers led by Xianpeng Liu at North Carolina State University have now developed a smarter solution. Named MonoXiver, their method uses AI to extract 3D information directly from 2D photos. MonoXiver’s multi-step approach begins with a simple, off-the-shelf monocular camera. These devices use a single lens to roughly estimate 3D geometries in 2D images, based on image cues including shading and lighting, patterns and texture, and the apparent sizes of similar-looking objects. Based on these estimations, MonoXiver then identifies and encloses important objects in the image – like cars on a street – with a virtual 3D “bounding box.” The boxes help visualise the various scales, aspect ratios, and orientations of 3D objects in a scene.
At first, these bounding box positions are based on the crude estimates of the monocular camera – but using them as a starting point, MonoXiver the re-analyses the area contained inside them, and constructs a secondary group of smaller boxes, which capture many of the smaller details which weren’t indicated by the initial box. Using specialised models, MonoXiver can also determine when these small details overlap, and distinguish between them when they are crowded or close together. Finally, Liu’s team checked whether the details indicated by MonoXiver’s secondary boundary boxes matched what they actually saw in 2D photos. This involved testing whether the smaller boxes contained shapes, colours, and textures consistent with those in the larger initial box.