
NLP aims to establish communication between humans and computers. A chatbot like ChatGPT needs first to understand the written text by the user and then generate a new text as a response. Based on that NLP covers two subtopics which are Natural Language Understanding (NLU) and Natural Language Generation (NLG).
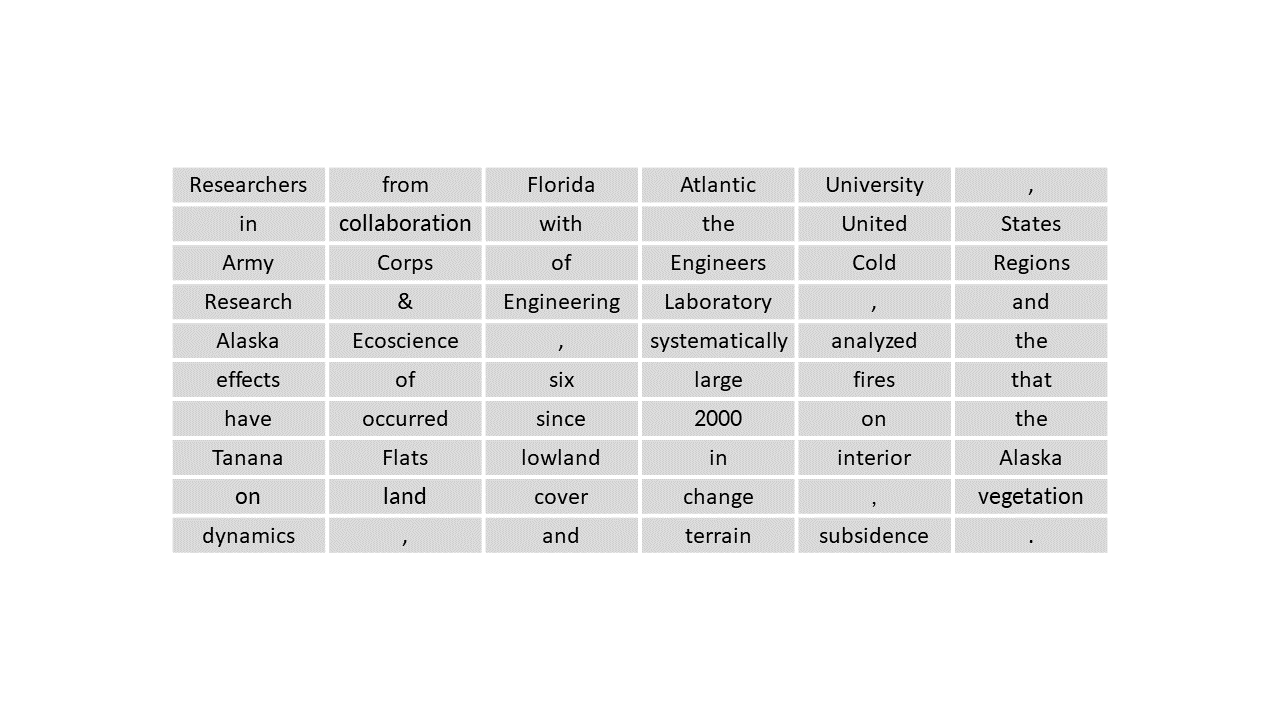
Assume that we have a raster image that represents a text. Based on the application, the pixels can be words, terms, or sentences. In NLP, representing text in a rester-like form is called Text Tokenization. Based on the raw values, i.e., characters, we assign new arbitrary values to pixels to make the raster more interpretable. For example, in Part of Speech (POS) Tagging, the values would be Noun, Verb, Adjective, Adverb, and so on. This example is analogous to identifying pixels that refer to agricultural areas. In the next step, we recognize each pixel’s crop type. In NLP literature, it is known as Named Entity Recognition (NER), in which we assign labels such as Person, Location, Organization, Date, Event, etc., to each token. Now, we know what the text is about.


NLU put further step and bring the computer more near to the meaning of the text. It involves Natural Language Inference (NLI) & Paraphrasing, Semantic Parsing, Dialogue Agents, Summarization, Question Answering, and Sentiment Analysis.
On the other hand, NLG focuses on producing a text similar to human-written ones, i.e., a readable text for humans. Generating real estate property descriptions, explaining products, and reporting weather can be automatically realized. In such examples, contrary to NLU, we have machine-readable data (structured data) and want human-readable data (unstructured data), mainly in a textual form. In another group of NLG applications like automated journalism, machine translation, and automated abstract generation (broadly known as Text Summarization), and answering to the user’s prompt, the input and the output are textual contents. Common applications between NLU and NLG mean that the chatbot (in general, the machine) should first understand the input text and then generate the output text. However, the beating heart of these applications is Language Modeling.
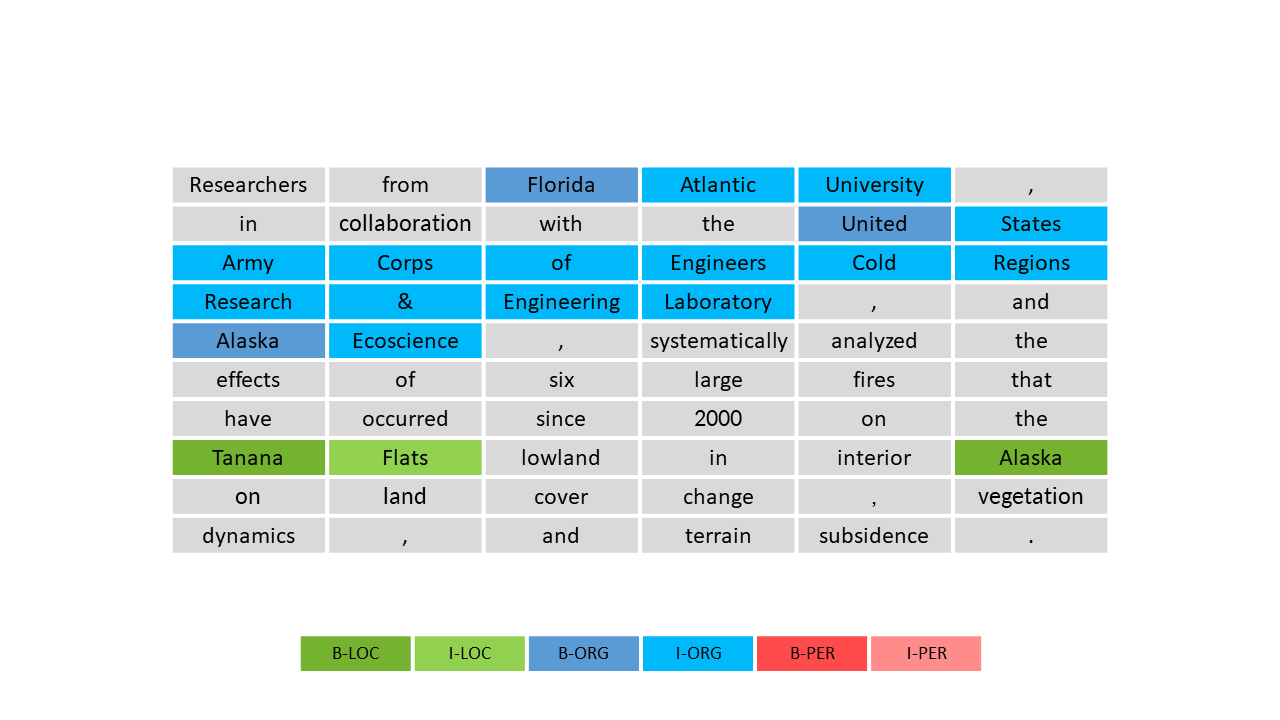
Language models predict generating the sentence with specific words for a given incomplete sentence. A language model is a probability distribution over sequences of words. For instance, suppose we have the incomplete sentence I love geographic. Based on occurrences of such sentences in the past, the language model would predict that the next word is more likely to be information.
A bag-of-words model (a.k.a Unigram Language Model), as the simplest type, estimates the probability of generating the sentence based on the previous tokens without paying attention to their order (i.e., a set of tokens). In the mentioned example, by using a bag-of-words model, there is not any difference between generating the sentence I geographic love information and I love geographic information. Although it seems awkward, that is an efficient way for some basic applications. For example, to implement a text classification task (e.g., topic labeling of news stories), we represent all texts of the collection in a matrix in that its columns (features) are unique words (the vocabulary) and the rows (records) are documents (news stories). The values can be simply binary (indicating that the document contains the word), counts (TF), or counts*rarity (TF-IDF).
In a more complex type, we assume that for generating a sequence ending a certain word, the N words before it is important. If we take n=2, we would have a Bigram Language Model. In the example I love geographic information science as the complete sentence, rather than estimating the probability of generating love (P(love)) in multiplying probabilities, the model considers the conditional probability of P(love|I). For the subsequent tokens, we would have P(geographic|love), P(information|geographic), and P(science|information). For n=3 (Trigram Language Model), P(I love geographic information science) would be estimated by multiplying P(I), P(love|I), P(geographic|I love), P(information|love geographic), P(science|geographic information).

Neural language models use Word Embedding (encoding the meaning of the word in a real-valued vector) as a representation of words and neural networks to make predictions. By enlarging the volume of texts for training N-gram language models, increasing the number of unique words, and exponentially growing the number of possible sequences, we will face more data sparsity. To solve that, N-gram language models need to apply smoothing techniques. On the other hand, Neural language models avoid the problem. Since neural language models aren’t limited to N, they can better capture long-range dependencies between words than N-gram language models. In addition, they can generalize better to unseen words by using word embedding techniques. Nonetheless, N-gram language models are simpler, fast to train and use than neural language models. Additionally, while neural network methods are mainly considered as black boxes that produce outputs without explanations, N-gram language models are transparent and interpretable.
A neural language model has three main components as follows:
Neural language models can be trained on large text corpora using back-propagation and gradient descent algorithms. They can also be fine-tuned or adapted to specific domains or tasks by adding additional layers or parameters. Bidirectional Encoder Representations from Transformers (BERT), Generative Pre-trained Transformer (GPT), Embeddings from Language Model (ELMo), and XLNet are popular examples of neural language models.
Alongside Supervised Learning and Unsupervised Learning, Reinforcement Learning is one of three basic machine learning paradigms. In RL, a computer agent learns to perform a task through repeated trial-and-error interactions with a dynamic environment. The agent receives feedback from the environment through rewards or punishments and adjusts its actions to maximize the total rewards.
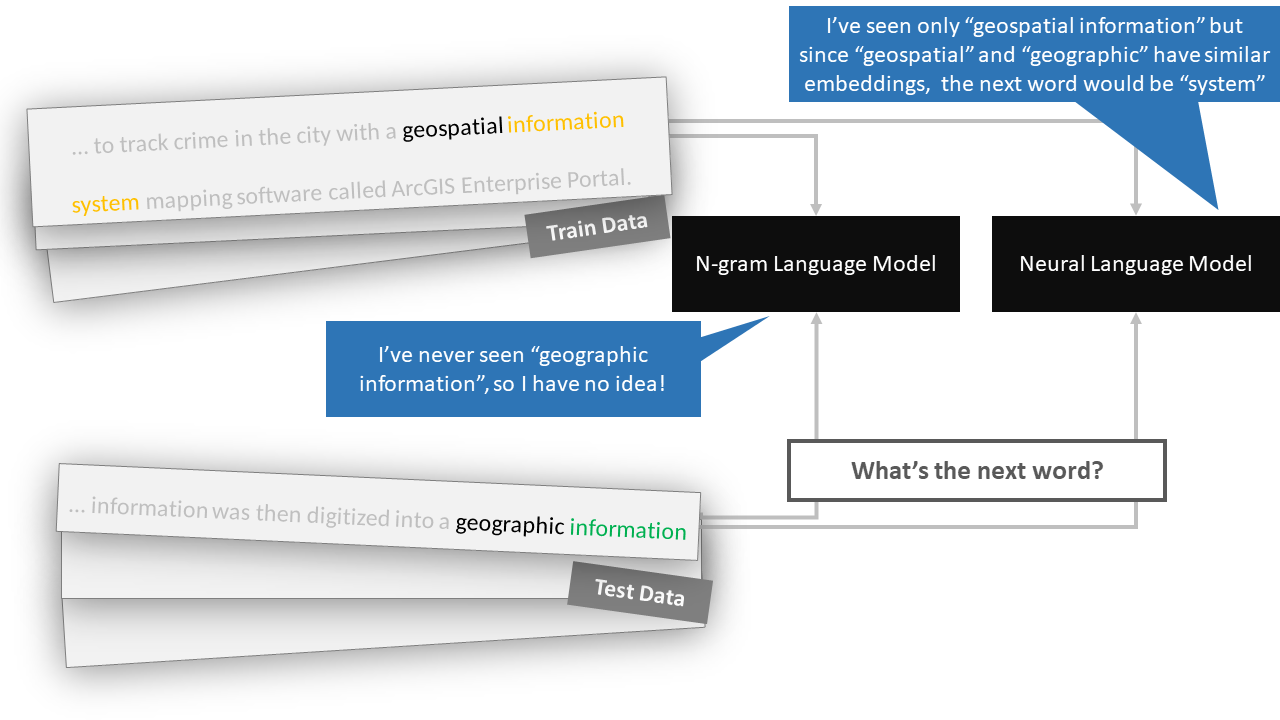
A language model learned to predict the next word in a text sequence requires additional work to understand the language deeper. Although ChatGPT is based on the GPT-3 language model, it is also further trained in a reinforcement learning process using human feedback. This technique is called Reinforcement Learning from Human Feedback and has three steps:
A list of prompts (e.g., what is the future of geospatial technology?) is collected. Human labelers write the expected response (e.g., Geospatial technology is … Some of the future trends of geospatial technology is …). Part of the prompts are prepared by the developers, and another group includes the sampled ones from OpenAI’s API requests. After data collection, they fine-tuned the pre-trained model (GPT-3.5). Due to limited data, the supervised fine-tuned model suffers from high scalability costs. The next step is defined to overcome that.
Rather than preparing a huge volume of prompts and answers, the developers defined a reinforcement learning process. The labelers rank the several answers generated by the SFT model for each prompt to train the reward model.
A proximal policy optimization algorithm is applied to adapt the current policy continuously. The environment presents a random prompt and expects a response. Accordingly, the trained reward model gives a reward for this action.
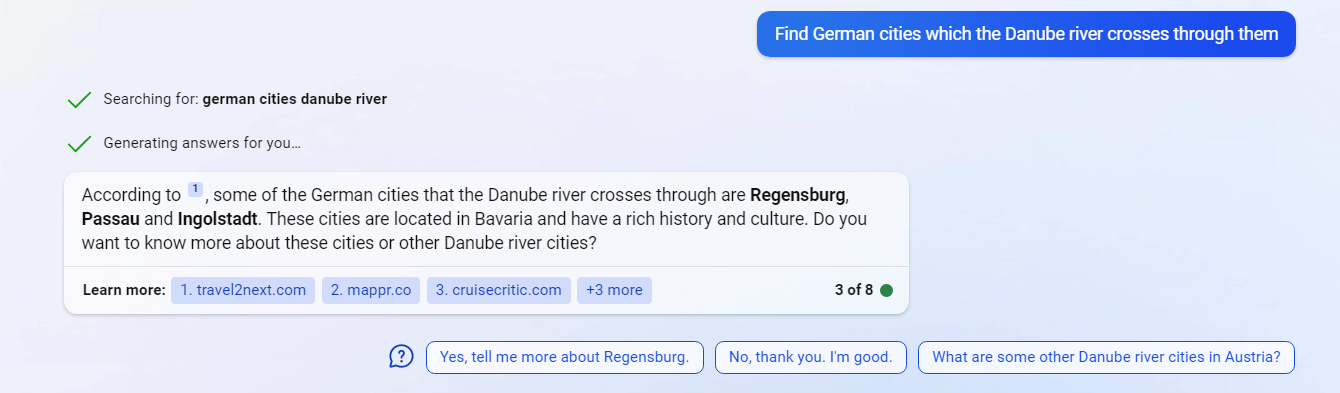
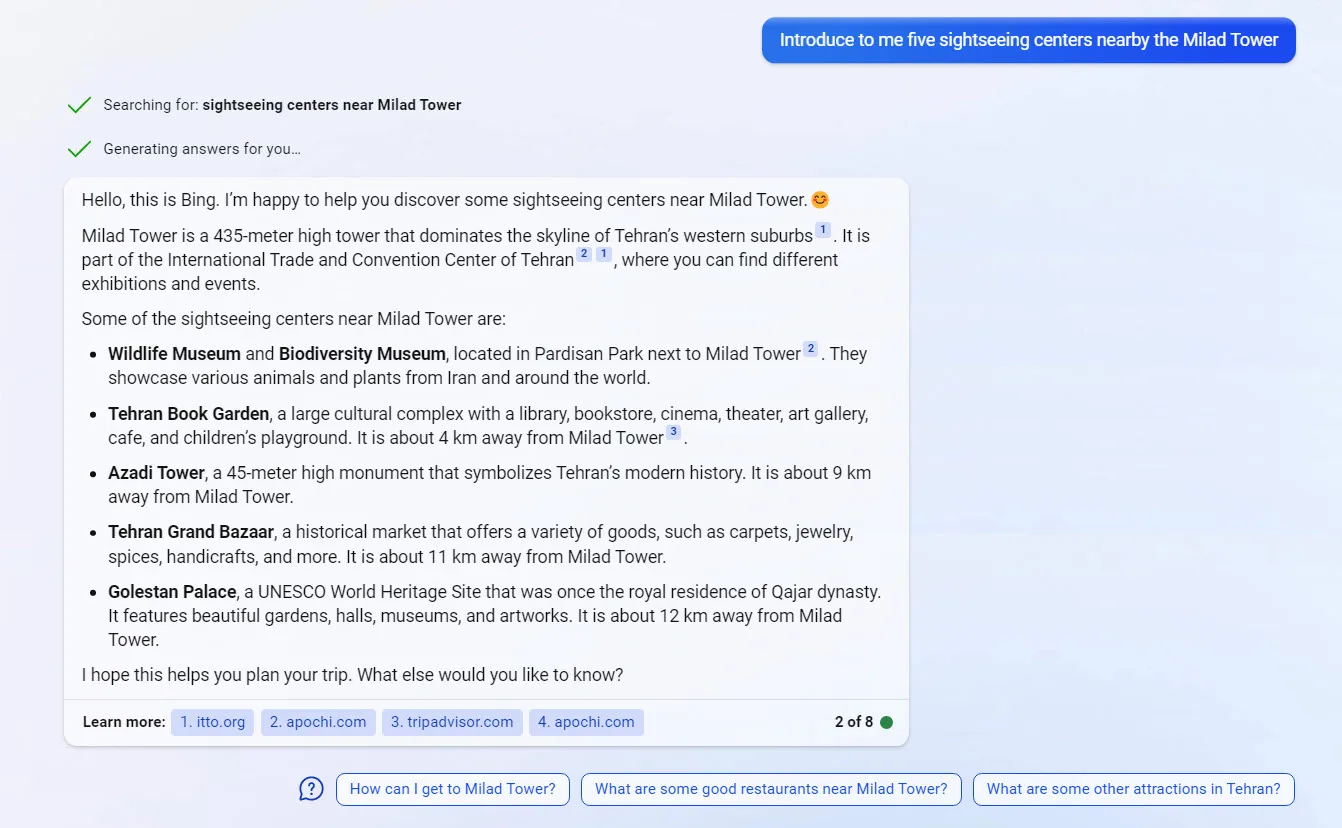
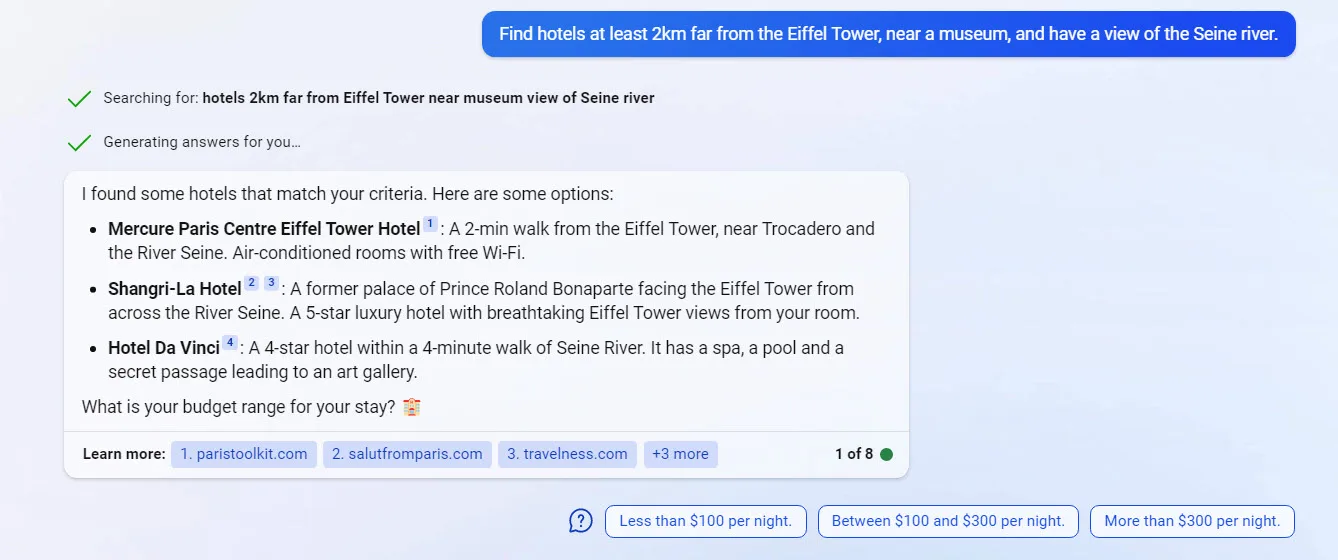
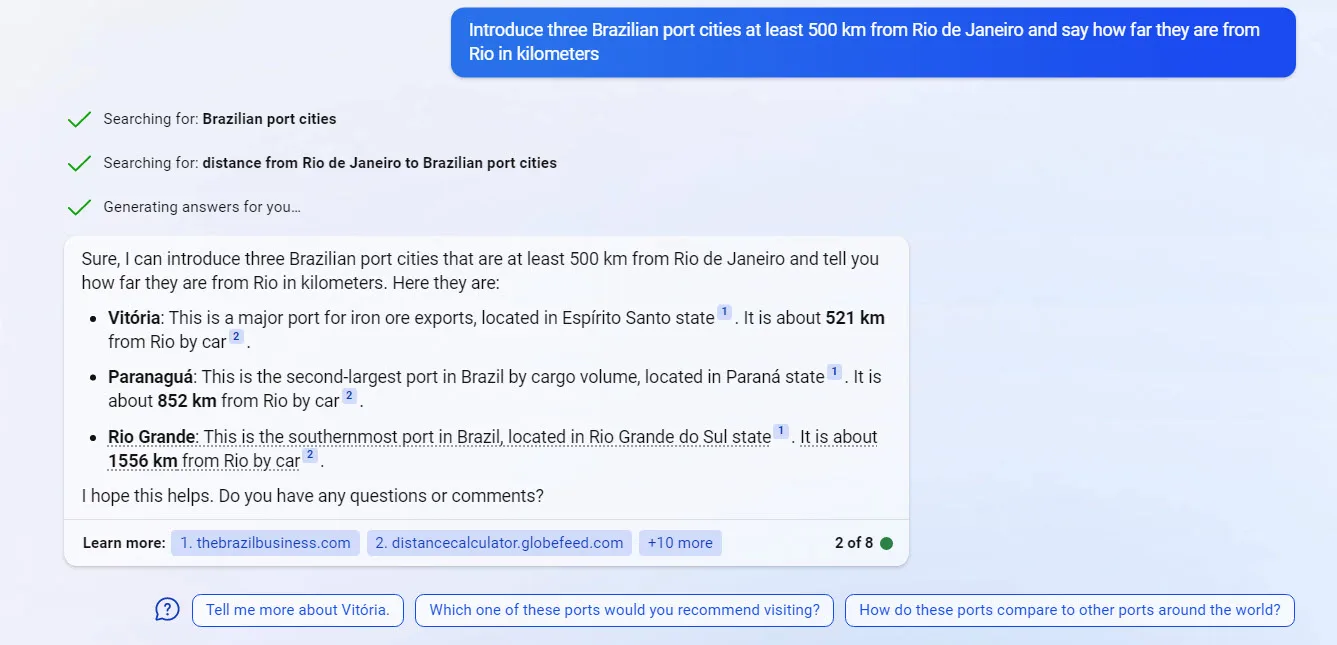
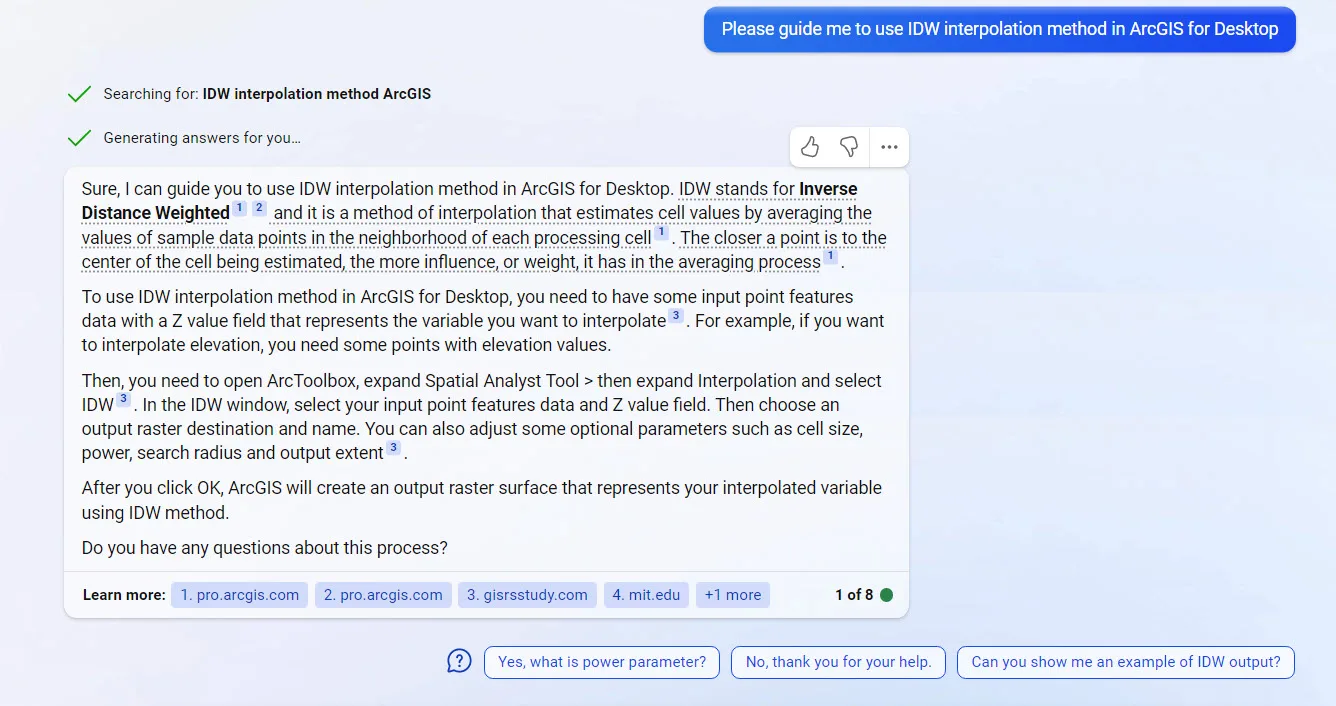
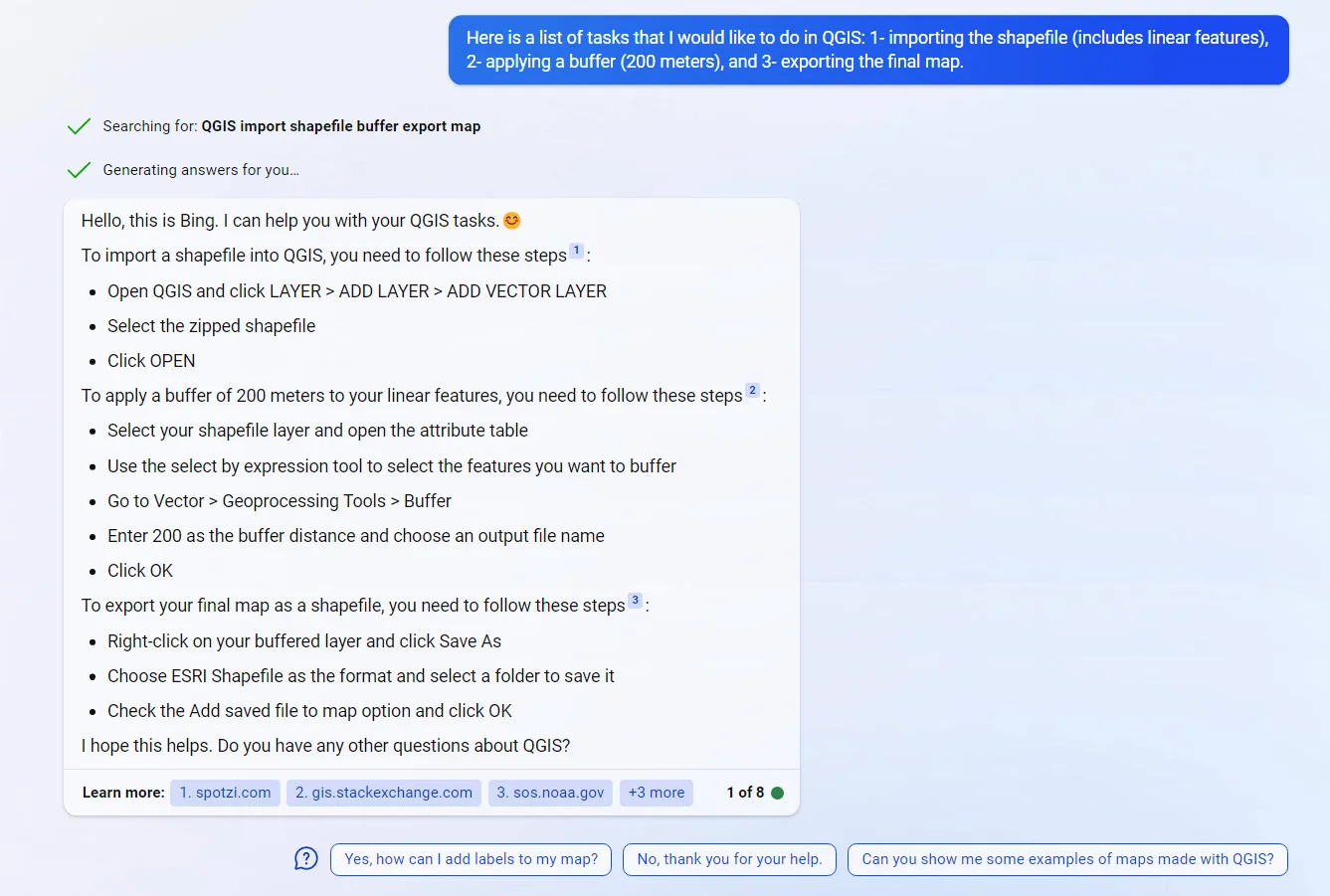
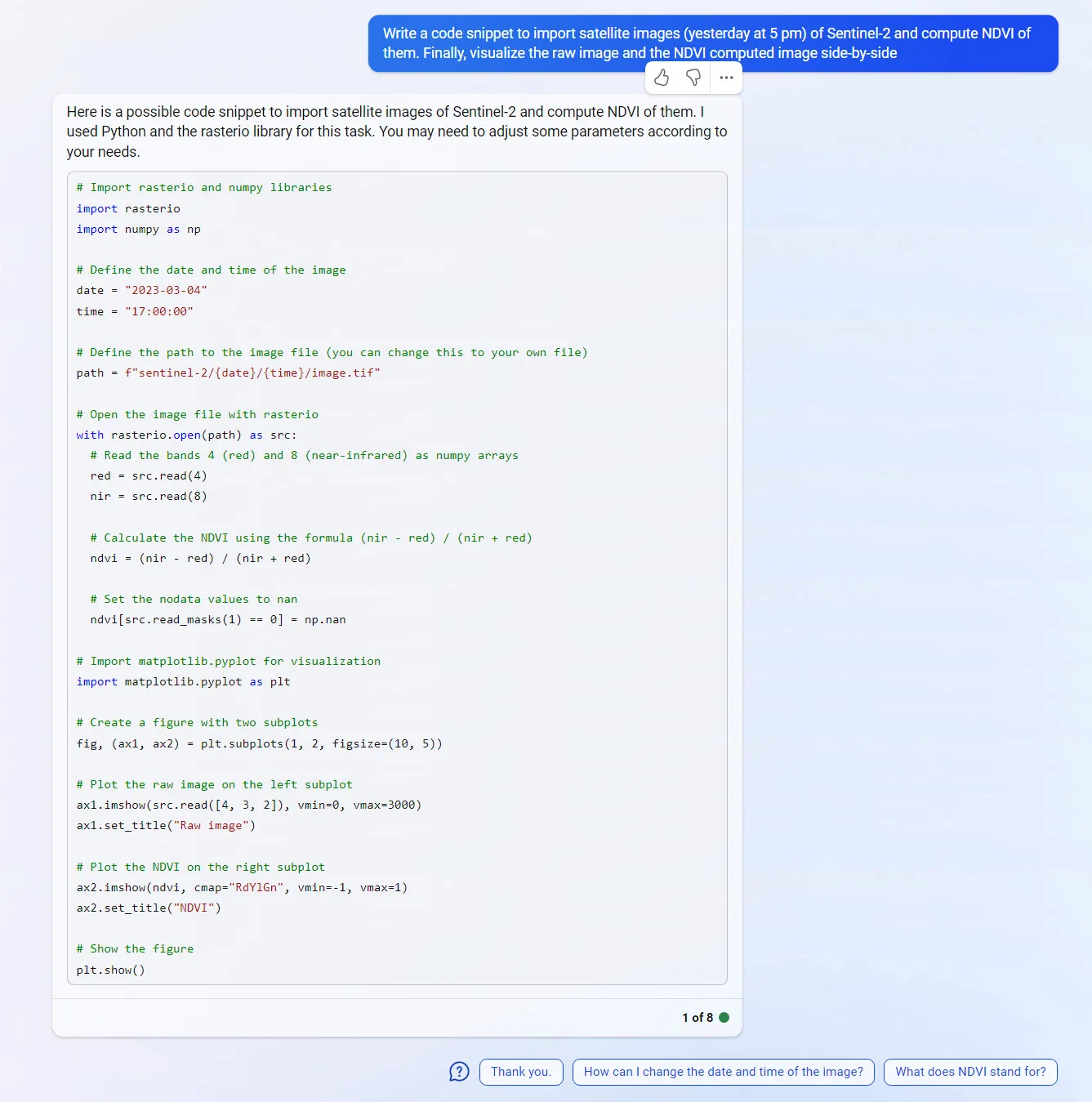
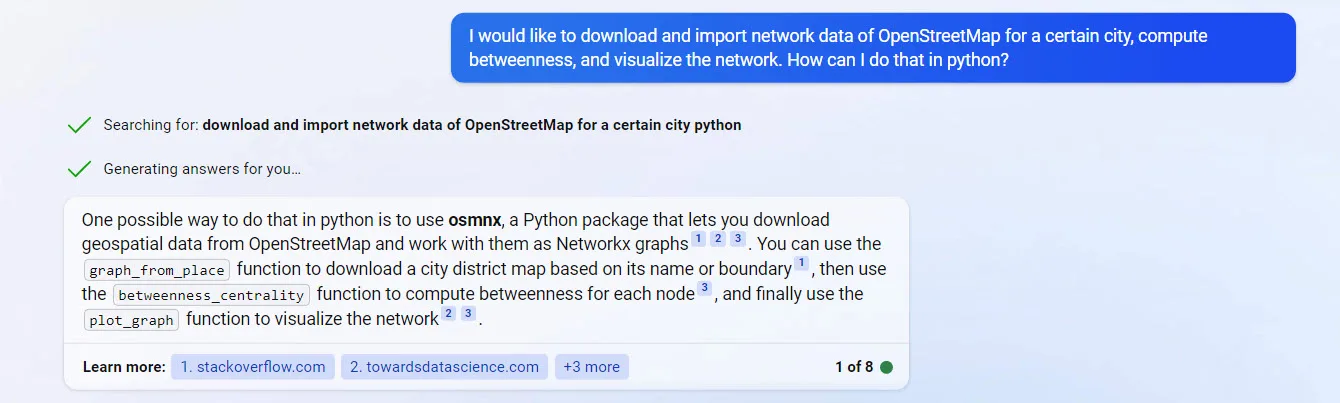
Due to mentioned advantages of the New Bing, the examples provided in the following sections were asked from the New Bing.
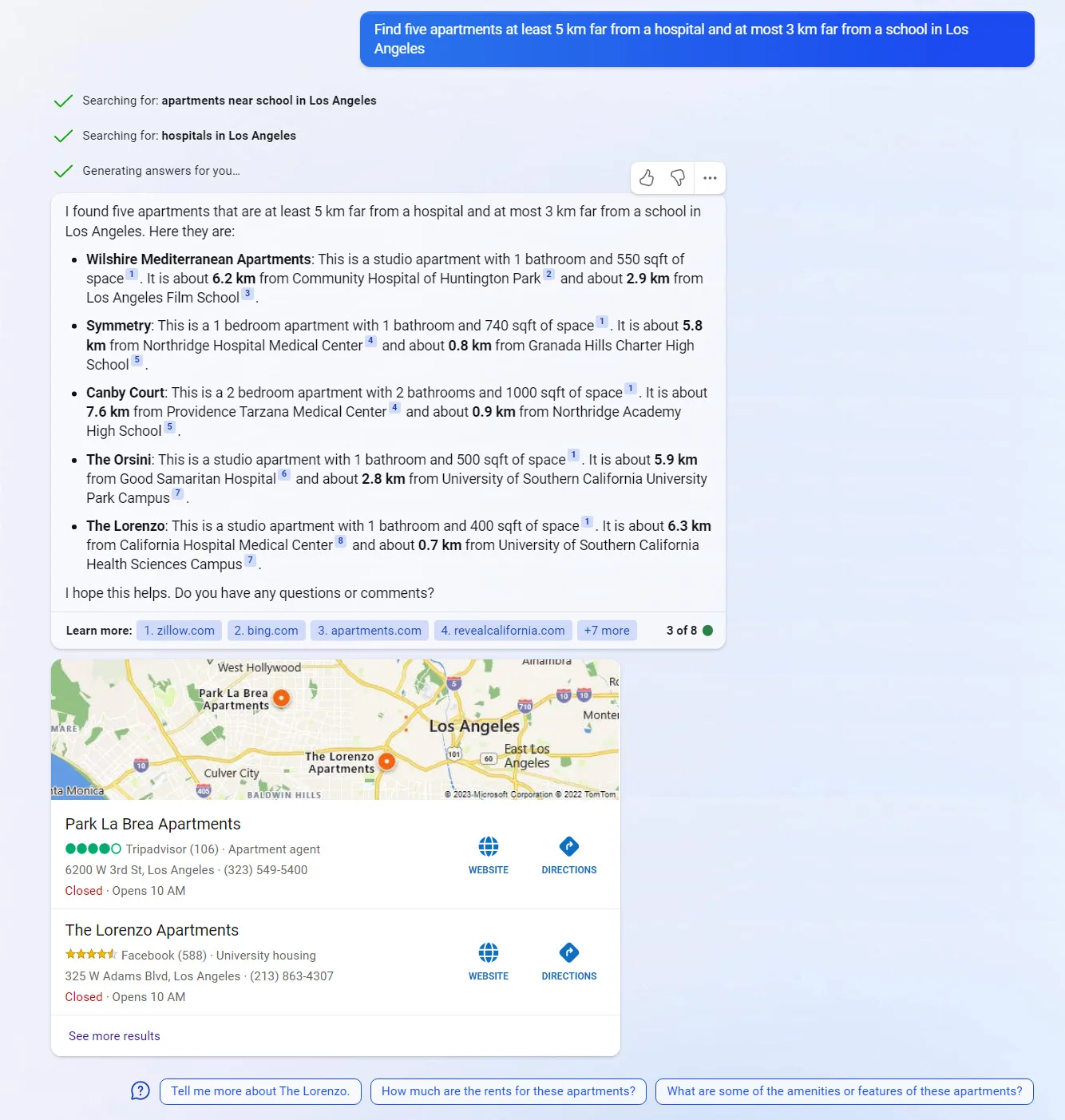
Contents